분당서울대학교병원 소아청소년과 김경훈 교수팀이 소아 환자의 천명음(wheezing)을 분류할 수 있는 트랜스포머(Transformer) 기반 인공지능(AI) 모델을 개발했다. 이 모델의 천명음 분류 정확도는 91.1%로 임상에서도 활용이 가능할 것으로 기대된다.
천명음은 기도가 좁아지거나 막혀 발생하는 고음의 ‘쌕쌕’거리는 호흡음이다. 주로 소아 천식이나 만성 폐쇄성 폐질환 등의 호흡기 질환에서 나타나기 때문에 호흡기 질환을 조기 진단하는 데 중요한 지표로 사용되고 있다.
현재 천명음에 대한 진단은 의료진이 환자의 가슴에 청진기를 대고 직접 호흡음을 듣는 방식에 의존하고 있다. 그러나 이는 의료진의 숙련도와 경험에 따라 정확도가 달라지는 주관적인 방법이기에 객관적이고 정확한 진단법의 필요성이 제기돼 왔다.
이런 필요성에 따라 최근까지는 소리를 이미지처럼 변환해 분석하는 AI 기술인 ‘합성공 신경망(Convolutional Neural Network, CNN)’을 이용한 연구가 진행돼 왔다. 하지만 CNN은 주로 이미지 인식 분야에서 성능을 인정받고 있는 기술로, 소리를 특정한 짧은 시간 단위로만 분리 · 분석하는 구조라 호흡 전체의 흐름이나 앞뒤 연결 관계를 파악하는 데에는 한계가 있었다.

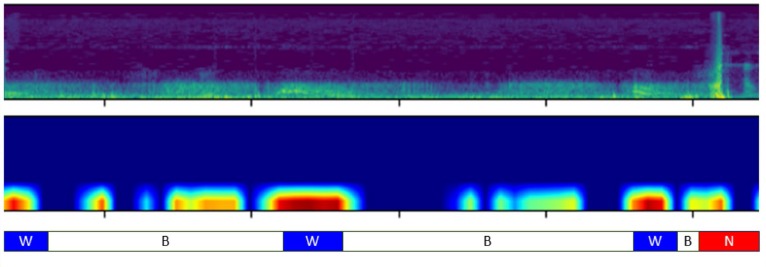
연구팀이 개발한 AST 모델은 소리를 주파수 형태의 이미지로 변환한 ‘멜 스펙트로그램(Mel Spectrogram)’을 16x16 크기의 작은 조각으로 나누고, 조각 간의 관계를 학습하는 방식으로 설계되었다. 즉, 전체적인 호흡 흐름에 대한 정보에 기반해 천명음의 패턴을 정밀하게 파악하는 방식으로, 이는 일부 정보만 분석하는 CNN과는 구조적인 차이점이 있다.
연구팀은 천명음 194개와 기타 호흡음(심장 소리 포함) 531개 등 총 725개 호흡음 중 80%를 AST 모델에 학습시켰다. 그리고 천명음과 기타 호흡음 전체에 대한 객관적인 평가를 위해 소아 폐 전문의 2명이 각각 독립적으로 평가를 진행했다.
이후 AST와 CNN 모델을 활용해 나머지 20%의 호흡음에 대해 천명음을 구분해 내는 분류 성능을 비교했다. 그 결과 AST 모델은 정확도 91.1%, 정밀도 88.2%를 나타냈다. AI 모델이 실제로 우수한 성능을 나타내는지 평가하는 ‘F1-Score’ 역시 82.2%로 나타나 CNN 보다 분류 성능이 우수하다는 사실을 확인할 수 있었다.
연구팀은 이 같은 결과에 대해 “AST 모델은 전체 호흡음의 문맥을 학습할 수 있는 구조로 설계된 만큼, 일부 정보만 분석하는 CNN 보다 훨씬 정밀한 분류가 가능하다”고 설명했다.
또한 AST 모델은 전처리 과정에서의 데이터 손실이 적고 모델 자체가 경량화 돼 모바일기기에서도 구동할 수가 있다. 이는 향후 임상 현장에서 스마트기기를 활용한 빠르고 정밀한 진단에도 큰 도움이 될 것으로 보인다.
분당서울대병원 소아청소년과 김경훈 교수는 “소아는 성인보다 폐포의 표면적이 작아 호흡기 질환에 더 취약한 만큼 천명음을 정확히 구분하는 게 조기진단에 매우 중요한 부분”이라며, “이번 결과를 통해 AI 기반 AST 모델의 소아 호흡음 분석 기술을 임상에 적용할 가능성을 입증했다”고 말했다.
이어 “스마트기기에 적용해 실시간 진단에 활용하고, 의료 접근성이 낮은 지역에서도 정확한 천명음 진단이 가능할 수 있도록 후속 연구·개발을 추진할 계획”이라고 덧붙였다.
한편, 이번 연구 결과는 네이처 출판 그룹의 온라인 학술지 ‘Scientific Reports’ 최신 호에 실렸다.
<저작권자 ⓒ 헬스위크, 무단 전재 및 재배포 금지>
전훈아 기자 다른기사보기